Arya Farkhondeh
Machine Learning & Computer Vision Engineer
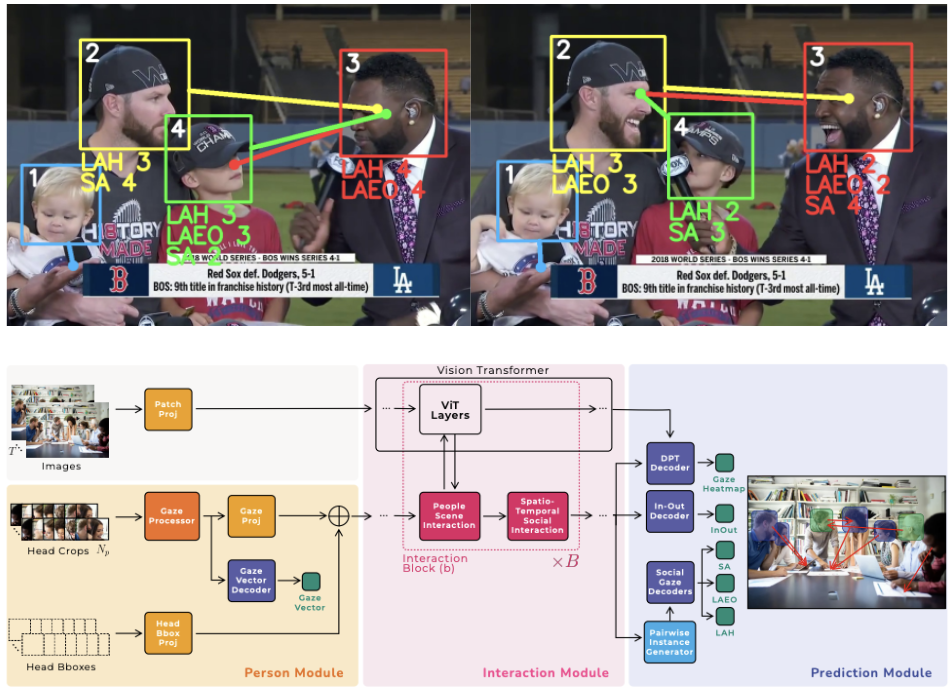
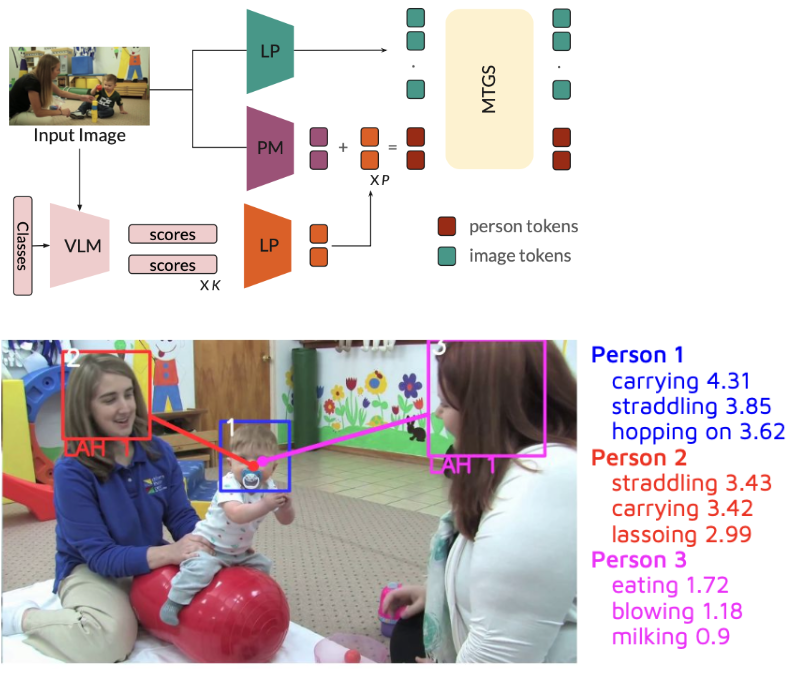
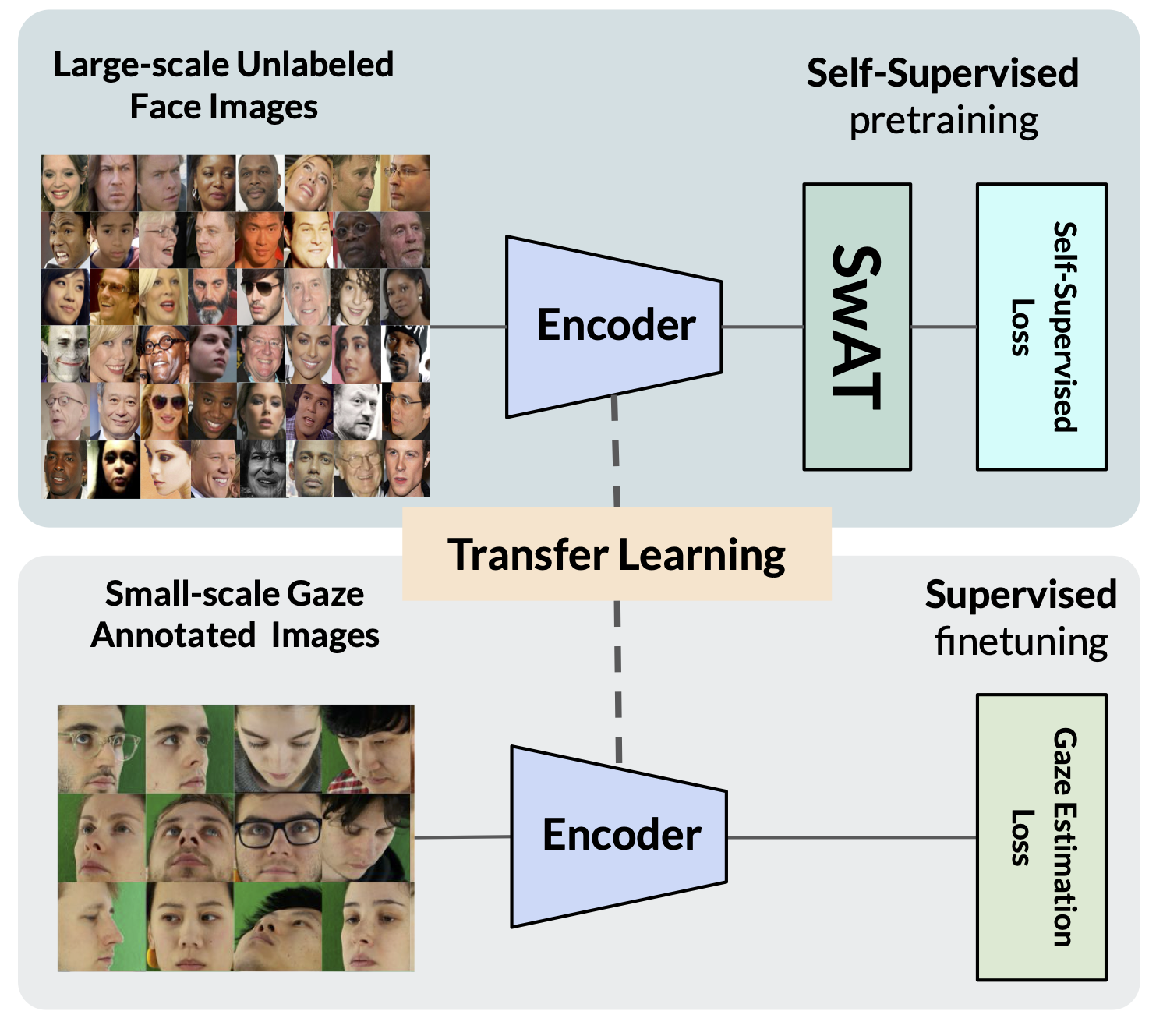
I develop AI systems for understanding how humans interact with objects and their environment. My work spans hand-object interaction, action understanding, gaze estimation, visual attention, and multimodal human behavior analysis.
Currently, I work as a Machine Learning Engineer at Simi Automotive (ZF LIFETEC), building in‑cabin intelligence for functional safety and automated driving. Previously, I worked at Idiap Research Institute, EPFL, and the Computer Vision Center (CVC).